Machine Learning Engineer (Ads) Interview Questions
A Guide to Pass the MLE interview.
pytorch必须掌握的的4种学习率衰减策略 理解深度学习中的学习率及多种选择策略
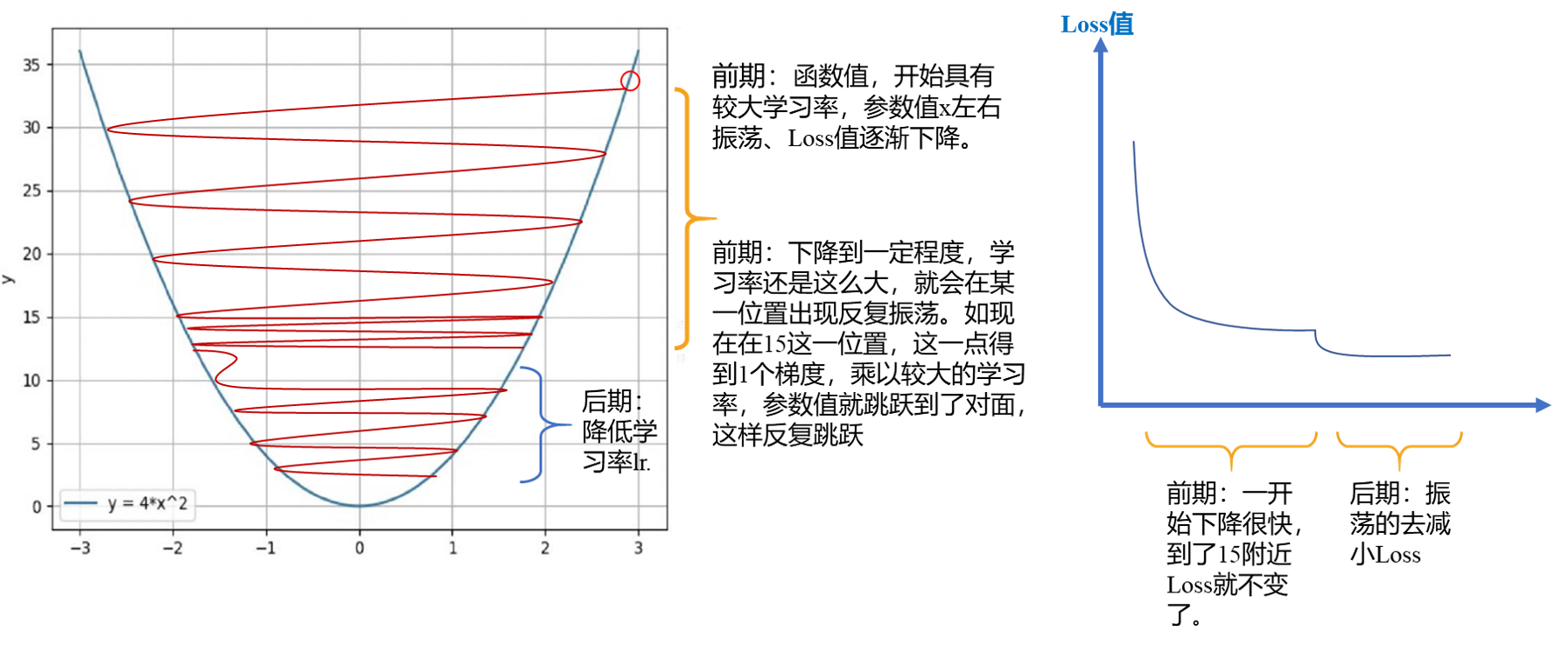
1 为什么要调整学习率?
通常,在模型训练过程中,学习率给的比较大,这样可以让模型参数在初期更新比较快;到了后期,学习率有所下降,让参数更新的步伐减慢。可是,为什么会在模型训练时对学习率采用 “前期大、后期小” 的赋值特点呢?
2 学习率衰减策略
需要注意学习率衰减策略很大程度上是依赖于经验与具体问题的,不能照搬参数。
2.1 指数衰减
首先定义一个优化器:
optimizer_ExpLR = torch.optim.SGD(net.parameters(), lr=0.1)
定义好优化器以后,就可以给这个优化器绑定一个指数衰减学习率控制器:
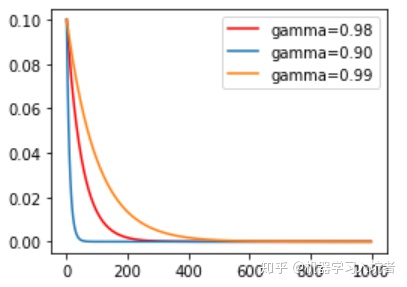
ExpLR = torch.optim.lr_scheduler.ExponentialLR(optimizer_ExpLR, gamma=0.98)
其中参数gamma表示衰减的底数,选择不同的gamma值可以获得幅度不同的衰减曲线,如下:
2.2 固定步长衰减
有时我们希望学习率每隔一定步数(或者epoch)就减少为原来的gamma分之一,使用固定步长衰减依旧先定义优化器,再给优化器绑定StepLR对象:
optimizer_StepLR = torch.optim.SGD(net.parameters(), lr=0.1)
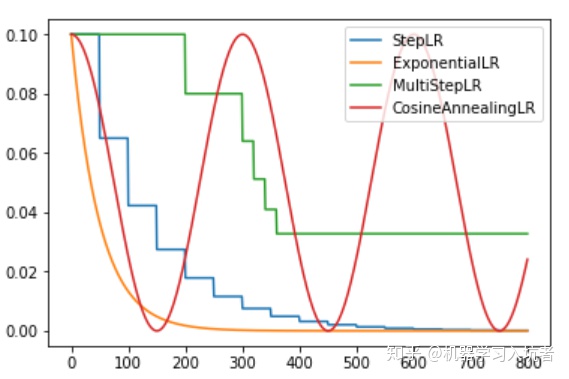
StepLR = torch.optim.lr_scheduler.StepLR(optimizer_StepLR, step_size=step_size, gamma=0.65)其中gamma参数表示衰减的程度,step_size参数表示每隔多少个step进行一次学习率调整,下面对比了不同gamma值下的学习率变化情况:
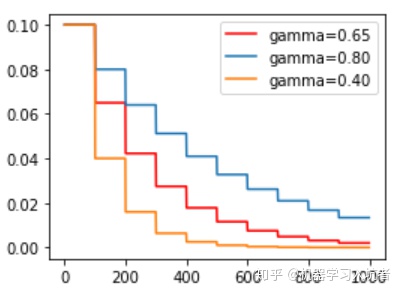
2.3 多步长衰减
上述固定步长的衰减的虽然能够按照固定的区间长度进行学习率更新,但是有时我们希望不同的区间采用不同的更新频率,或者是有的区间更新学习率,有的区间不更新学习率,这就需要使用MultiStepLR来实现动态区间长度控制:
optimizer_MultiStepLR = torch.optim.SGD(net.parameters(), lr=0.1)
torch.optim.lr_scheduler.MultiStepLR(optimizer_MultiStepLR, milestones=[200, 300, 320, 340, 400], gamma=0.8)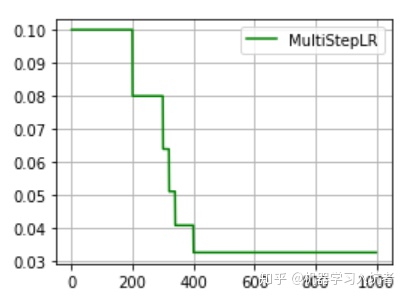
从图中可以看出,学习率在区间[200,400]内快速的下降,这就是milestones参数所控制的,在milestones以外的区间学习率始终保持不变。
2.4 余弦退火
严格的说,余弦退火策略不应该算是学习率衰减策略,因为它使得学习率按照周期变化,其定义方式如下:
optimizer_CosineLR = torch.optim.SGD(net.parameters(), lr=0.1)
CosineLR = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_CosineLR, T_max=150, eta_min=0)其包含的参数和余弦知识一致,参数T_max表示余弦函数周期;eta_min表示学习率的最小值,默认它是0表示学习率至少为正值。确定一个余弦函数需要知道最值和周期,其中周期就是T_max,最值是初始学习率。下图展示了不同周期下的余弦学习率更新曲线:
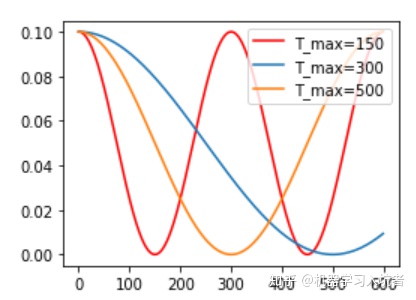
3 如何选择初始学习率?
可以以非常低的学习率开始训练模型,在每一次迭代过程中逐渐提高学习率(线性提高或是指数提高都可以),用户可以用这种方法估计出最佳学习率。
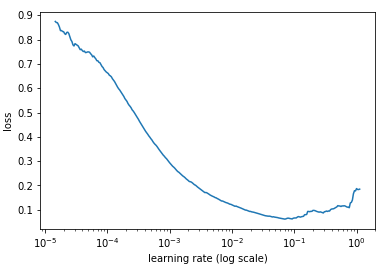
在每一个 mini-batch 后提升学习率
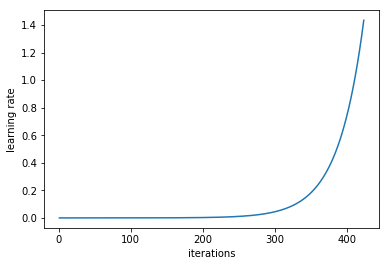
如果我们对每次迭代的学习进行记录,并绘制学习率(对数尺度)与损失,我们会看到,随着学习率的提高,从某个点开始损失会停止下降并开始提高。在实践中,学习速率的理想情况应该是从图的左边到最低点(如下图所示)。在本例中,是从 0.001 到 0.01。