Machine Learning Engineer (Ads) Interview Questions
A Guide to Pass the MLE interview.
1 RNN
1.1 模型图
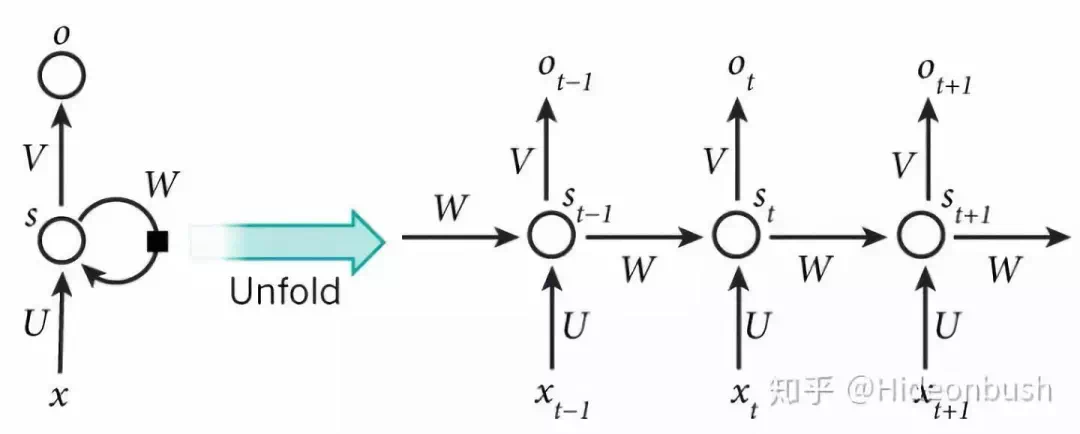
1.2 RNN梯度消失与爆炸的原因
由于\(W_h\)的权值共享,当\(W_h\)的最大特征值大于或小于1 就会累积\(W_h^n\),所以造成梯度消失或者爆炸
梯度消失的问题:远处的信息(梯度)会消失,会对之后的输入没有影响
梯度爆炸的问题:每次迈出的步太大,导致无法收敛
1.3 缓解梯度爆炸的方法:梯度裁剪(Gradient Clipping)
2 LSTM
2.1 模型图
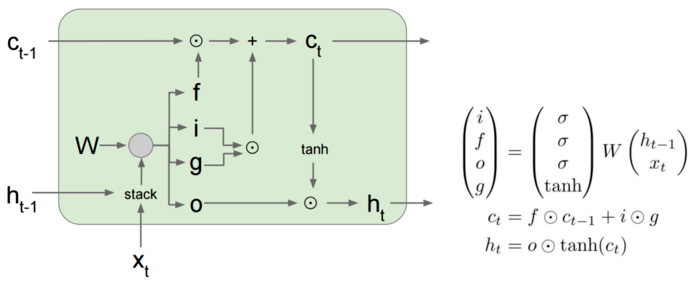
2.2 LSTM如何缓解梯度消失和爆炸问题
rnn只能单线传输之前的所有hidden state(H),而lstm有两条线cell state(C)和hidden state(H)。因此lstm解决了rnn单线传输的问题,防止长期信息丢失。以及梯度消失和爆炸。

- h:隐藏层,同rnn
- c:记忆单元,lstm新增模块,防止遗忘
- forget门:控制过去的c遗忘多少(0-1)
- input门:控制写入多少当前的c
- output门:控制多少c写入h
- 三个门都和过去的h:\(h^{(t-1)}\)以及现在的x:\(x^{(t)}\)相关
2.3 为何门控要用sigmoid,传播要用tanh?
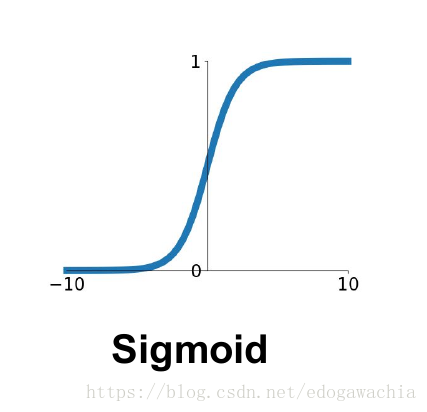
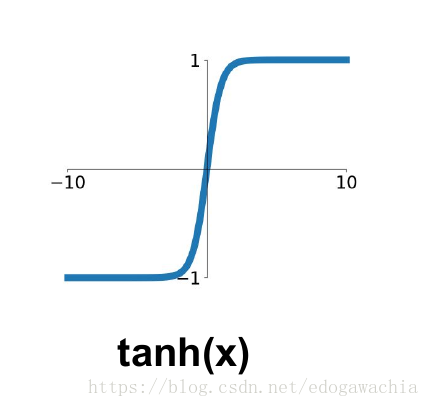
Sigmoid的输出在0-1之同,符合门控的物理定义,且当输入较大或较小时,其输出会非常接近1或0,从而保证该门开或关,在生成候选记亿时,使用tanh函数,是因为其输出在-1-1之间,这与大多数场景下特征分布是0中心的吻合。此外,输入在0周围时,tanh相比Sigmoid函数有更大的梯度,通常使模型收敛更快。
3 GRU
3.1 模型图
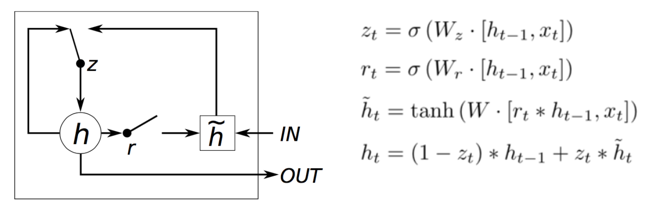
GRU是lstm的简化,只有两个门,减少了参数。也没有了cell state。 rt用来控制上一轮的h在这轮的输入大小,ut控制新旧的比例。 这里巧妙的地方在于ut。新的和旧的权重和为1。
4 LSTM和GRU如何解决了RNN的问题?
总结:LSTM和GRU都是通过门控机制缓解RNN梯度消失与爆炸的问题
5 Scaled Dot-Product Attention
- attention为什么要除以根号下dk
6 Multi-head attention
7 Self-attention
self-attention 到底比seq2seq的attention优越在哪里?(最好结合业务场景说一说)
self attention是有resnet的结构的,现在有不同流派一个是加在LN层后一个是加在前面,各有什么优势之类的?
8 Transformer
QK的放缩因子
decoder的mask层是如何设计的
介绍下Multi-head Attention,为什么需要多头注意力?
transformer的Position-wise Feed-Forward Networks为什么需要降维升维。
encoder层介绍一下
9 BERT
- 什么时候用BERT?什么时候用GPT?
10 Embedding
详细解释Embedding(词向量发展史和graph embedding)
怎么得到一句话里的关键词,要求结合语义;